Goroutine是什么
众所周知,操作系统拥有进程和线程,进程是资源分配的最小单位,线程是CPU调度的最小单位,协程是比线程更小的一种执行单元,blablabla这些都太理论了。
就拿我们日常使用电脑的例子来说明,打开浏览器程序,就是创建了一个新进程,打开三个网页标签页,就是在这个进程下创建了三个线程。
为了更好地说明协程,先举个简单的例子,假设现在有一个煤矿厂,里面有一条工作流水线:挖煤 -> 运煤 -> 烧煤。
这时候,煤矿厂的老板想要获得更高的产能,有很多方式。
进程
最容易想到的就是再开一个煤矿厂 :P
进程之间的资源是相互独立的,也就是有独立的矿山、独立的小推车、独立的火炉,两者互不干扰。
线程
在一个矿场里设立更多的流水线,我们现在还是只有一个矿山和一个火炉,那在多条流水线的情况下,就需要考虑资源的调度。比如流水线1在把煤矿运到火炉的时候,发现流水线2还在占用火炉,而且占用好久了,这时候矿场老板可以让流水线2暂停,让流水线1开始使用火炉。
线程之间可以共享进程的资源,合理使用和调度多线程可以更好地利用资源。
协程
拆分流水线的工作,分成三个人分别完成挖煤、运煤和烧煤。并且设立一个包工头,包工头可以调度这些工人。
比如有工人A用了好久的火炉,这时候包工头会让工人A歇一歇,让等在一旁的工人B来使用火炉。
上述的例子与概念的对应关系为:
| 例子 | 概念 |
|---|---|
| 所有的煤矿、推车、火炉 | 系统资源 |
| 老板 | 操作系统 |
| 一整个运作的矿场 | 进程 |
| 一条流水线 | 线程 |
| 工人的工作(挖煤、运煤、烧煤) | 协程 |
| 包工头 | 用户态下协程的调度器 |
简单来说,进程、线程、协程三者创建所耗费的资源是逐渐降低的,所以可以用更小的粒度控制程序和更少的切换时带来的消耗。
Goroutine
Go的Goroutine是用户级的线程。同样是4个Goroutine,可能只对应了2个内核级线程。Goroutine调度器把4个Goroutine分配到2个内核级线程上,而这两个内核级线程对CPU的使用由内核线程调度器来分配。
由于线程可以由操作系统调度管理,而goroutine是user-level下的,所以只能由Go runtime自己负责goroutine的调度。Goroutines的调度是协作式的,而线程不是。这意味着每次一个线程发生切换,都需要保存/恢复所有寄存器,包括16个通用寄存器、PC(程序计数器)、SP(栈指针)、段寄存器(segment register)、16个XMM寄存器、FP协处理器状态、X AVX寄存器以及所有MSR等。而当另一个Goroutine被调度时,只需要保存/恢复三个寄存器,分别是PC、SP和DX。Go调度器和任何现代操作 系统的调度器都是O(1)复杂度的,这意味着增加线程/goroutines的数量不会增加切换时间,但改变寄存器的代价是不可忽视的。
Goroutine调度模型
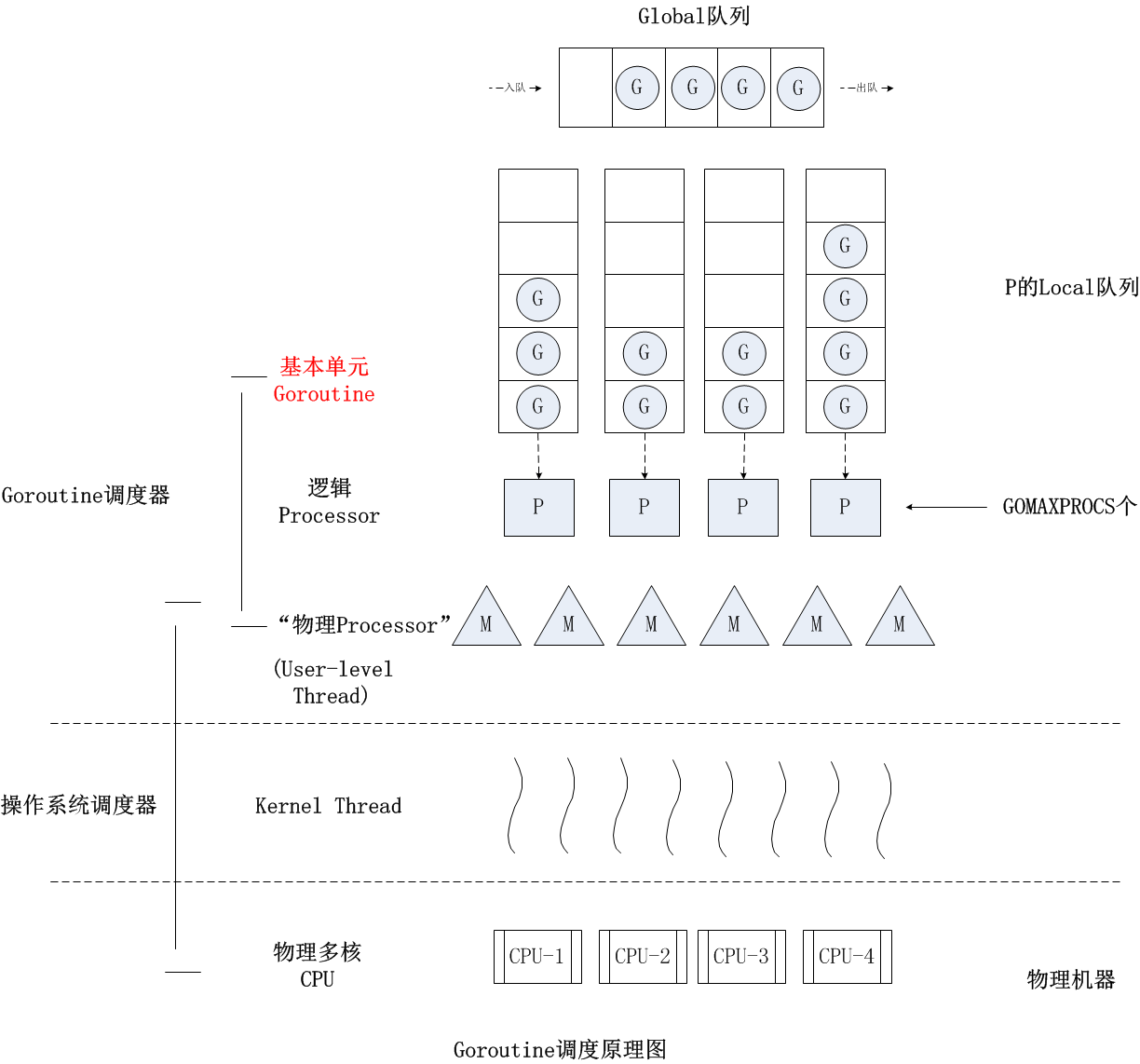
P是一个“逻辑 Proccessor”,每个G要想真正运行起来,首先需要被分配一个P(进入到 P 的 local runq 中,这里暂忽略 global runq 那个环节)。对于 G 来说,P 就是运行它的 “CPU”,可以说:G 的眼里只有 P。但从 Go scheduler 视角来看,真正的 “CPU” 是 M,只有将 P 和 M 绑定才能让 P 的 runq 中 G 得以真实运行起来。这样的 P 与 M 的关系,就好比 Linux 操作系统调度层面用户线程 (user thread) 与核心线程 (kernel thread) 的对应关系那样,都是 (n × m) 模型。具体来说:
- G: 表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
- P: 表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
- M: M代表着真正的执行计算资源。在绑定有效的p后,进入schedule循环;而schedule循环的机制大致是从各种队列、p的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到m,如此反复。M并不保留G状态,这是G可以跨M调度的基础。
Goroutine抢占调度
一个 goroutine 获得计算资源(CPU)后一般不能一直运行到完毕,它们往往可能要等待其他资源才能执行完成,比如读取磁盘文件内容、通过RPC调用远程服务等,在等待的过程中 goroutine 是不需要消耗计算资源的,因此调度器可以把计算资源给其他的 goroutine 使用。
goroutine 遇到下面的情况下可能会产生重新调度:
- 阻塞 I/O
- select操作
- 阻塞在channel
- 等待锁
- 主动调用 runtime.Gosched()
如果一个 goroutine 不包含上面提到的几种情况,那么其他的 goroutine 就无法被调度到相应的 CPU 上面运行,这是不应该发生的。这时候就需要抢占机制来打断长时间占用 CPU 资源的 goroutine ,发起重新调度。
而且如果设置GOMAXPROCS=1,其中的一个goroutine不主动调用runtime.Gosched()则会永远执行下去,其他的G就会被“饿死”。于是Dmitry Vyukov又提出了《Go Preemptive Scheduler Design》并在Go 1.2中实现了“抢占式”调度。
这个抢占式调度的原理则是在每个函数或方法的入口,加上一段额外的代码,让runtime有机会检查是否需要执行抢占调度。这种解决方案只能说局部解决了“饿死”问题,对于没有函数调用,纯算法循环计算的G,调度器依然无法抢占。
Go程序启动时,runtime会去启动一个名为sysmon的m(一般称为监控线程),该m无需绑定p即可运行,该m在整个Go程序的运行过程中至关重要,sysmon 可以找出长时间占用(forcePreemptNS默认为10ms)的 goroutine,并将该goroutine的抢占标志位被设为true,这样在这个goroutine下次调用函数的时候就会发生调度,被移入P的local runq,等待下一次的调度。
sysmon每20us~10ms启动一次,主要完成如下工作:
- 释放闲置超过5分钟的span物理内存
- 如果超过2分钟没有垃圾回收,强制执行
- 将长时间未处理的netpoll结果添加到任务队列
- 向长时间运行的G任务发出抢占调度
- 收回因syscall长时间阻塞的P
学以致用
1 |
|
上面代码应该会输出
1 | Index: 1, Now: 10386200 ns |
因为goroutine1的for循环里面是没有调用函数的,所以不会被插入编译器插入额外抢占调度的检测代码,但由于超过了10ms,该goroutine的抢占标志位已经被设为true了,所以执行到fmt.Printf()的时候发生了调度,开始执行另一个goroutine的代码,最后发生了panic。
后记
本人才疏学浅,本文写得也比较仓促,如有错误,敬请斧正!