线程安全的map 众所周知,go中的map不是线程安全的,两个线程(或协程)同时修改map中同一个key的value,会产生不确定的结果。而在golang中,遇到这种情况,程序会panic退出,个人觉得这样严苛的限制可以迫使开发者明白自己在写什么,以免未来陷入排查并发问题的痛苦之中。
关于go开发者关于设计非并发安全的map的初衷可以看这里:
Go maps in action
Why are map operations not defined to be atomic?
目前运用比较广泛的有三种线程安全的map实现方法:
性能比较 测试环境 测试平台:
硬件
配置
CPU
i7-9700K 8C8T
RAM
32G
OS
Win10 专业工作站版
go版本:
1 2 $ go version go version go1.14.2 windows/amd64
测试结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ go test -bench=. -benchtime=3s -benchmem goos: windows goarch: amd64 BenchmarkMap_Set-8 3681 967422 ns/op 159212 B/op 19901 allocs/op BenchmarkMap_Get-8 4568 791230 ns/op 39614 B/op 9901 allocs/op BenchmarkMutexMap_Set-8 1164 3028656 ns/op 163996 B/op 19946 allocs/op BenchmarkMutexMap_Get-8 1735 2094115 ns/op 39895 B/op 9903 allocs/op BenchmarkSyncMap_Set-8 1022 3673158 ns/op 486904 B/op 39981 allocs/op BenchmarkSyncMap_Get-8 1562 2315195 ns/op 39908 B/op 9903 allocs/op BenchmarkConcurrentMap_Set-8 1346 2639138 ns/op 159914 B/op 19908 allocs/op BenchmarkConcurrentMap_Get-8 1528 2343214 ns/op 39799 B/op 9902 allocs/op PASS ok _/D_/projects/test/go/map/benchmark 30.852s
结果分析 首先创建长度均为10000的MutexMap、SyncMap和ConcurrentMap三种并发安全的map,然后分别循环10000次的并发写入和并发读取,具体代码见下方。
BenchmarkMap_Set 和 BenchmarkMap_Get是非并发安全的基准测试
上述结果表明单独并发写入的时候,concurrent-map形式的map性能最好,mutex+map次之,sync.Map排在最后。
比较反直觉的是,为什么利用分段锁原理实现的concurrent-map性能还不如一整把大锁的mutex+map。理论上来说,并发性能应该随着分段锁数量的增长而增长。
上述被删除的话是因为之前benchmark代码写错了而导致的错误结论,具体原因是由于concurrent-map库实现的时候底层结构是map[string]interface{},而我在与之比较的mutex+map用的却是map[string]int
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 package mainimport ( "github.com/orcaman/concurrent-map" "math/rand" "strconv" "sync" "testing" ) var N = 10000 var simpleMap map [string ]interface {}var mutexMap MutexMapvar syncMap sync.Mapvar concurrentMap cmap.ConcurrentMapfunc init () simpleMap = make (map [string ]interface {}, N) mutexMap = MutexMap{m: make (map [string ]interface {}, N)} syncMap = sync.Map{} for i:=0 ; i<N; i++ { syncMap.Store(strconv.Itoa(i), i) } concurrentMap = cmap.New() for i:=0 ; i<N; i++ { concurrentMap.Set(strconv.Itoa(i), i) } } func BenchmarkMap_Set (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { idx := rand.Intn(N) simpleMap[strconv.Itoa(idx)] = j + 1 wg.Done() } wg.Wait() } } func BenchmarkMap_Get (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { idx := rand.Intn(N) _ = simpleMap[strconv.Itoa(idx)] wg.Done() } wg.Wait() } } func BenchmarkMutexMap_Set (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) mutexMap.Set(strconv.Itoa(idx), j+1 ) wg.Done() }() } wg.Wait() } } func BenchmarkMutexMap_Get (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) mutexMap.Get(strconv.Itoa(idx)) wg.Done() }() } wg.Wait() } } func BenchmarkSyncMap_Set (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) syncMap.Store(strconv.Itoa(idx), j+1 ) wg.Done() }() } wg.Wait() } } func BenchmarkSyncMap_Get (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) syncMap.Load(strconv.Itoa(idx)) wg.Done() }() } wg.Wait() } } func BenchmarkConcurrentMap_Set (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) concurrentMap.Set(strconv.Itoa(idx), j+1 ) wg.Done() }() } wg.Wait() } } func BenchmarkConcurrentMap_Get (b *testing.B) for i:=0 ; i<b.N; i++ { wg := sync.WaitGroup{} wg.Add(N) for j:=0 ; j<N; j++ { go func () idx := rand.Intn(N) concurrentMap.Get(strconv.Itoa(idx)) wg.Done() }() } wg.Wait() } } type MutexMap struct { sync.RWMutex m map [string ]interface {} } func (m *MutexMap) string , v interface {}) { m.Lock() m.m[k] = v m.Unlock() } func (m *MutexMap) string ) (v interface {}) { m.RLock() v = m.m[k] m.RUnlock() return }
进阶分析 mutex+map这种并发安全的map实现方式简单来说,就是在整个map上加了一把大锁。
而concurrent-map和java的ConcurrentHashMap整体思路大致相同,都是分段锁,减小锁的粒度换来更高并发性能的思想。
理论上,分成两段锁的map写入性能应该是一把大锁的map的两倍,但实际情况,还需要考虑寻找分段时的损耗以及上下文的切换。
下面我简单实现了一下分段锁的map,并测试了一下不同分段数量下的性能比较。
main.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 package mainimport "sync" const PRIME32 = uint32 (16777619 )type ConcurrentMap struct { ShardCount int items []*ConcurrentMapShard } type ConcurrentMapShard struct { sync.RWMutex m map [string ]interface {} } func New (log2OfShardCount int ) shardCount := 1 <<log2OfShardCount m := ConcurrentMap{ ShardCount: shardCount, items: make ([]*ConcurrentMapShard, shardCount), } for i := 0 ; i < shardCount; i++ { m.items[i] = &ConcurrentMapShard{m: make (map [string ]interface {})} } return m } func (m ConcurrentMap) string ) *ConcurrentMapShard { return m.items[uint (fnv32(key)) & uint (m.ShardCount-1 )] } func (m ConcurrentMap) string , value interface {}) { shard := m.GetShard(key) shard.Lock() shard.m[key] = value shard.Unlock() } func (m ConcurrentMap) string ) (interface {}, bool ) { shard := m.GetShard(key) shard.RLock() val, ok := shard.m[key] shard.RUnlock() return val, ok } func fnv32 (key string ) uint32 { hash := uint32 (2166136261 ) length := len (key) for i := 0 ; i < length; i++ { hash *= PRIME32 hash ^= uint32 (key[i]) } return hash }
其中New(log2OfShardCount int)表示创建的段数为2的幂,是为了上篇文章golang map 实现原理初探 中提到的性能优化方式:n mod m = n & (m - 1)
主要测试逻辑是,创建长度为10000的各种map,然后每个goroutine读或写100次map
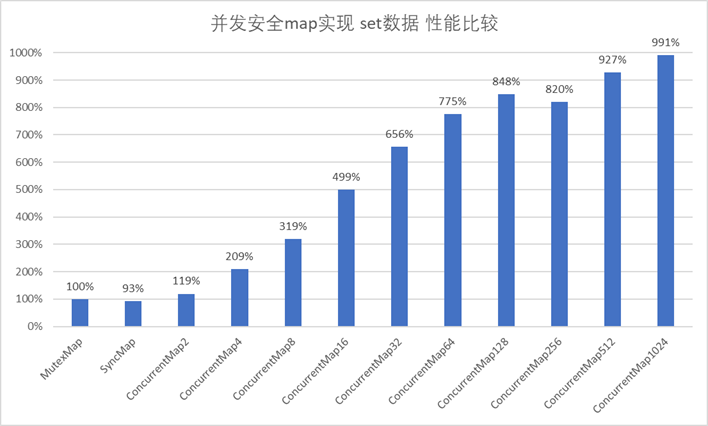
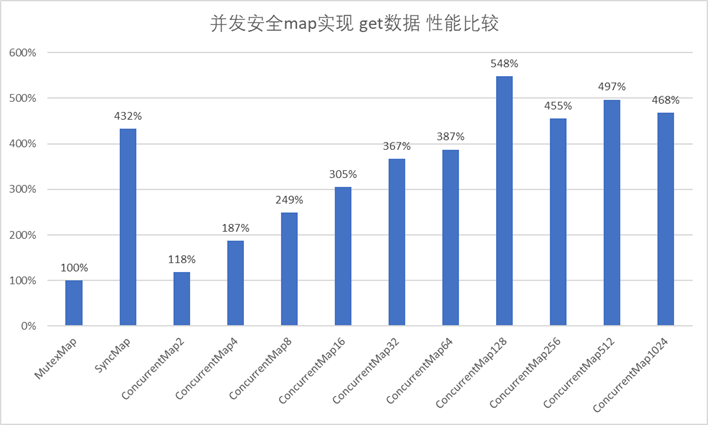
实验结果 实验环境同上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 $ go test -bench=. -benchmem goos: windows goarch: amd64 BenchmarkMap_Set-8 169460 6822 ns/op 1592 B/op 199 allocs/op BenchmarkMap_Get-8 227022 5354 ns/op 388 B/op 99 allocs/op BenchmarkMutexMap_Set-8 49311 27208 ns/op 2037 B/op 201 allocs/op BenchmarkMutexMap_Get-8 245551 6101 ns/op 702 B/op 100 allocs/op BenchmarkSyncMap_Set-8 45951 29188 ns/op 4871 B/op 400 allocs/op BenchmarkSyncMap_Get-8 1000000 1411 ns/op 380 B/op 67 allocs/op BenchmarkConcurrentMap2_Set-8 59857 22799 ns/op 1688 B/op 200 allocs/op BenchmarkConcurrentMap2_Get-8 256150 5159 ns/op 399 B/op 99 allocs/op BenchmarkConcurrentMap4_Set-8 92553 13020 ns/op 1678 B/op 200 allocs/op BenchmarkConcurrentMap4_Get-8 376006 3255 ns/op 382 B/op 99 allocs/op BenchmarkConcurrentMap8_Set-8 150399 8531 ns/op 1653 B/op 200 allocs/op BenchmarkConcurrentMap8_Get-8 501336 2453 ns/op 398 B/op 99 allocs/op BenchmarkConcurrentMap16_Set-8 250670 5453 ns/op 1648 B/op 200 allocs/op BenchmarkConcurrentMap16_Get-8 668452 1998 ns/op 425 B/op 99 allocs/op BenchmarkConcurrentMap32_Set-8 364605 4146 ns/op 1626 B/op 200 allocs/op BenchmarkConcurrentMap32_Get-8 859450 1661 ns/op 395 B/op 99 allocs/op BenchmarkConcurrentMap64_Set-8 462778 3510 ns/op 1667 B/op 200 allocs/op BenchmarkConcurrentMap64_Get-8 1000000 1576 ns/op 276 B/op 58 allocs/op BenchmarkConcurrentMap128_Set-8 534606 3207 ns/op 1671 B/op 200 allocs/op BenchmarkConcurrentMap128_Get-8 1000000 1114 ns/op 151 B/op 32 allocs/op BenchmarkConcurrentMap256_Set-8 634191 3317 ns/op 1668 B/op 200 allocs/op BenchmarkConcurrentMap256_Get-8 1257463 1340 ns/op 416 B/op 99 allocs/op BenchmarkConcurrentMap512_Set-8 753351 2935 ns/op 1672 B/op 200 allocs/op BenchmarkConcurrentMap512_Get-8 1340647 1228 ns/op 374 B/op 99 allocs/op BenchmarkConcurrentMap1024_Set-8 752020 2745 ns/op 1667 B/op 200 allocs/op BenchmarkConcurrentMap1024_Get-8 1336896 1304 ns/op 400 B/op 99 allocs/op PASS ok _/D_/projects/test/go/map/benchmark 50.026s
结果分析
sync.Map的读取性能是MutexMap4.3倍,正如文档里所说的:
The Map type is optimized for two common use cases: (1) when the entry for a given key is only ever written once but read many times, as in caches that only grow, or (2) when multiple goroutines read, write, and overwrite entries for disjoint sets of keys. In these two cases, use of a Map may significantly reduce lock contention compared to a Go map paired with a separate Mutex or RWMutex.
主要适用于两个常见场景:
读多写少
多goroutine读、写、复写完全不同的key
从实验结果可以看出来,使用了分段锁的map有很大的读写性能提升。
但是和理论上的性能提升还有很大差距,而且分段数量也并不是越多越好。
所以当我们在设计高并发性能的程序时,需要权衡并发带来的性能提升和并发导致的开销。
代码 main_test.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 package mainimport ( "github.com/orcaman/concurrent-map" "strconv" "sync" "testing" ) var N = 10000 var simpleMap map [string ]interface {}var mutexMap MutexMapvar syncMap sync.Mapvar concurrentMap cmap.ConcurrentMapvar concurrentMap2 ConcurrentMapvar concurrentMap4 ConcurrentMaptype MutexMap struct { sync.RWMutex m map [string ]interface {} } func (m *MutexMap) string , v interface {}) { m.Lock() m.m[k] = v m.Unlock() } func (m *MutexMap) string ) (v interface {}) { m.RLock() v = m.m[k] m.RUnlock() return } func init () simpleMap = make (map [string ]interface {}, N) mutexMap = MutexMap{m: make (map [string ]interface {}, N)} syncMap = sync.Map{} for i := 0 ; i < N; i++ { syncMap.Store(strconv.Itoa(i), i) } concurrentMap = cmap.New() for i := 0 ; i < N; i++ { concurrentMap.Set(strconv.Itoa(i), i) } concurrentMap2 = New(1 ) for i := 0 ; i < N; i++ { concurrentMap2.Set(strconv.Itoa(i), i) } concurrentMap4 = New(2 ) for i := 0 ; i < N; i++ { concurrentMap4.Set(strconv.Itoa(i), i) } } func BenchmarkMap_Set (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { for j := 0 ; j < 100 ; j++ { simpleMap[strconv.Itoa((i+j)%N)] = i } finished <- true } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkMap_Get (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { for j := 0 ; j < 100 ; j++ { _ = simpleMap[strconv.Itoa((i+j)%N)] } finished <- true } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkMutexMap_Set (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { mutexMap.Set(strconv.Itoa((i+j)%N), i) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkMutexMap_Get (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { mutexMap.Get(strconv.Itoa((i+j)%N)) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkSyncMap_Set (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { syncMap.Store(strconv.Itoa((i+j)%N), i) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkSyncMap_Get (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { syncMap.Load(strconv.Itoa((i+j)%N)) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkConcurrentMap2_Set (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { concurrentMap2.Set(strconv.Itoa((i+j)%N), i) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkConcurrentMap2_Get (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { concurrentMap2.Get(strconv.Itoa((i+j)%N)) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkConcurrentMap4_Set (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { concurrentMap4.Set(strconv.Itoa((i+j)%N), i) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } } func BenchmarkConcurrentMap4_Get (b *testing.B) finished := make (chan bool , b.N) b.ResetTimer() for i := 0 ; i < b.N; i++ { go func () for j := 0 ; j < 100 ; j++ { concurrentMap4.Get(strconv.Itoa((i+j)%N)) } finished <- true }() } for i := 0 ; i < b.N; i++ { <- finished } }
benchmark如有错误或不妥的地方,请大家不吝赐教!