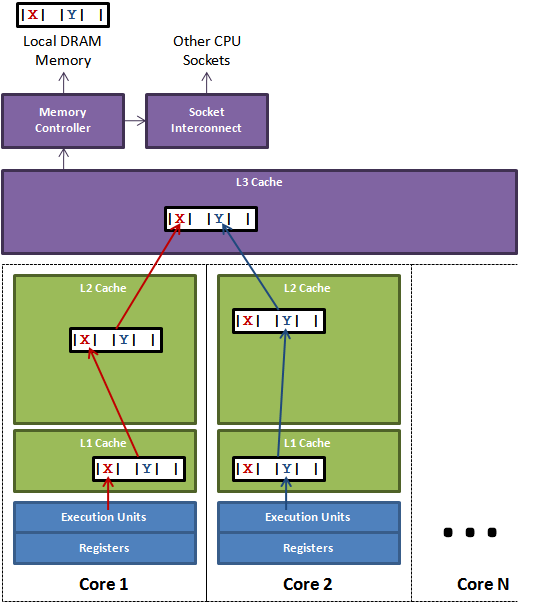
// StringHeader is the runtime representation of a string. // It cannot be used safely or portably and its representation may // change in a later release. // Moreover, the Data field is not sufficient to guarantee the data // it references will not be garbage collected, so programs must keep // a separate, correctly typed pointer to the underlying data. type StringHeader struct { Data uintptr Len int }
# unicorn['enable'] = true # unicorn['worker_timeout'] = 60 ###! Minimum worker_processes is 2 at this moment ###! See https://gitlab.com/gitlab-org/gitlab-ce/issues/18771 # unicorn['worker_processes'] = 2 # unicorn['worker_memory_limit_min'] = "250 * 1 << 20" # unicorn['worker_memory_limit_max'] = "400 * 1 << 20"
################################################################################ ## GitLab Puma ##! Tweak puma settings. You should only use Unicorn or Puma, not both. ##! Docs: https://docs.gitlab.com/omnibus/settings/puma.html ################################################################################
classSolution: defreverseList(self, head: ListNode) -> ListNode: new_list = None cur = head while cur != None: tmp = cur.next cur.next = new_list new_list = cur cur = tmp return new_list
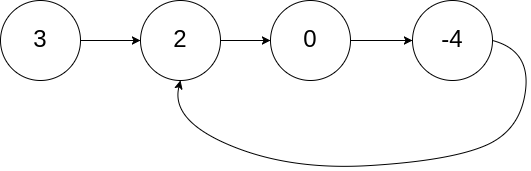
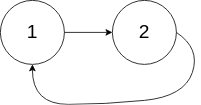
classSolution: defhasCycle(self, head: ListNode) -> bool: if head isNoneor head.nextisNone: returnFalse slow = head fast = head.next while slow != fast: if fast.nextisNoneor fast.next.nextisNone: returnFalse else: fast = fast.next.next slow = slow.next returnTrue
classSolution: defdetectCycle(self, head: ListNode) -> ListNode: if head isNoneor head.nextisNone: returnNone slow = head fast = head while fast isnotNoneand fast.nextisnotNone: fast = fast.next.next slow = slow.next if fast == slow: new_slow = head while new_slow != slow: new_slow = new_slow.next slow = slow.next return new_slow returnNone
classSolution: defmiddleNode(self, head: ListNode) -> ListNode: if head isNoneor head.nextisNone: return head middle = head cur = head i = 1 j = 1 while cur isnotNoneand cur.nextisnotNone: cur = cur.next j += 1 if i*2 <= j: i += 1 middle = middle.next return middle