Cache Line
数据经过主存、L3、L2、L1 Cache到CPU寄存器进行运算,访问的速度逐级提高,L3一般为多核共享,L2、L1一般为单核本地使用。
按照局部性原理,正在使用的数据的附近数据也大概率会被使用,所以CPU会按照Cache Line为一个单位加载一批连续的数据到缓存里,主流CPU一般为64B
例如你有一个数组,每个元素的类型为int64,大小为8B,当你用到第一个元素时,CPU会将另外7个元素也一起作为一个Cache Line加载到各级缓存中
什么是False sharing伪共享
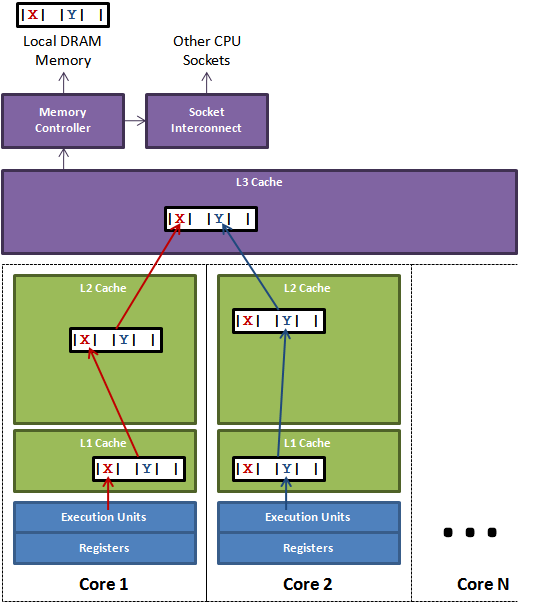
两个线程修改同一条Cache Line上的不同位置,发生了缓存不一致的情况,会导致L1、L2缓存上这条Cache Line被认为是无效数据
此时就需要MESI缓存一致性协议和RFO请求核间通信方式,来标记自己本地缓存上Cache Line的状态并通知另一个核是否需要更新缓存,最后通过相对比较慢的L3 Cache同步数据,甚至穿透到主存,总之这些都会带来开销
所以在这种情况下没有真正达到共享的目的,此为伪共享(其实应该翻译为错误共享)
那延伸一下,Cache Line如果大小为1B一个单位,只要不是修改到同一个字节的位置,那是不是就没有这个问题了?
但随之而来的是局部性的损失以及控制电路复杂度的提高,设计就是不断权衡利弊,这是另一个话题了
如何验证伪共享问题呢,我要眼见为实
复现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| package main
import (
"fmt"
"time"
)
type MyInt64 struct {
val int64
}
var (
N = 100000000
M = 8
List = new([8]MyInt64)
)
func run(idx int) {
for i:=N; i>0; i-- {
List[idx].val = int64(i)
}
}
func main() {
ch := make(chan int, M)
start := time.Now()
for i:=0; i<M; i++ {
go func(i int) {
run(i)
ch <- 1
}(i)
}
for i:=0; i<M; i++ {
<-ch
}
fmt.Printf("%v\n", time.Since(start))
}
|
我们构造一个长度为8的数组,每个元素都是一个大小为64bit的类型,共占64Byte
然后用8个协程分别更新各自索引位置的元素
执行 go run main.go
此时耗时约在秒级:2.5329389s
改进
如果我们加上一些padding,此时数组中每个元素都是64Byte的类型,每个元素都占满一个Cache,使得每个核操作不同的Cache Line
1
2
3
4
5
| type padding int64
type MyInt64 struct {
val int64 // 8Byte
pad1, pad2, pad3, pad4, pad5, pad6, pad7 padding // 56Byte
}
|
耗时约在百毫秒级别:113.9928ms
总结
所以可见,如果我们编写的程序恰巧遇到了False Sharing,会导致严重的性能问题。
目前perf-c2c等工具可以检测伪共享问题。开源的Disruptor框架也详细阐述了该问题
Golang在sync.Pool中也有对应的设计
1
2
3
4
5
6
7
| type poolLocal struct {
poolLocalInternal
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
|
但是真的结束了吗?
如果在上面的代码中不用数组,而是用slice会怎样?
slice底层是什么结构,会有什么影响?
1
2
3
4
5
| type slice struct {
array unsafe.Pointer
len int
cap int
}
|
如果改成8个pad会怎样?哪种对齐的结构对编译器更加友好?
(实际8个pad速度更快,可以试试)
7个pad
1
2
3
4
5
6
7
8
9
10
11
| MOVQ AX, SI
SHLQ $6, AX
MOVQ DX, (BX)(AX*1)
DECQ DX
MOVQ SI, AX
TESTQ DX, DX
JLE 71
MOVQ main.List+8(SB), CX
MOVQ main.List(SB), BX
NOP
CMPQ AX, CX
|
8个pad
1
2
3
4
5
6
7
8
| LEAQ (AX)(AX*8), SI
MOVQ DX, (BX)(SI*8)
DECQ DX
TESTQ DX, DX
JLE 56
MOVQ main.List(SB), BX
TESTB AL, (BX)
CMPQ AX, $8
|
如果关闭编译优化会怎样?或者说编译优化究竟在优化什么?
关闭编译优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| go build -gcflags="-N -l -S" main.go
0x000e 00014 (main.go:18) MOVQ AX, main.idx+40(SP)
0x0013 00019 (main.go:19) MOVQ main.N(SB), DX
0x001a 00026 (main.go:19) MOVQ DX, main.i+16(SP)
0x001f 00031 (main.go:19) NOP
0x0020 00032 (main.go:19) JMP 34
0x0022 00034 (main.go:19) CMPQ main.i+16(SP), $0
0x0028 00040 (main.go:19) JGT 44
0x002a 00042 (main.go:19) JMP 91
0x002c 00044 (main.go:20) MOVQ main.idx+40(SP), AX
0x0031 00049 (main.go:20) MOVQ main.List+8(SB), CX
0x0038 00056 (main.go:20) MOVQ main.List(SB), DX
0x003f 00063 (main.go:20) MOVQ main.i+16(SP), BX
0x0044 00068 (main.go:20) CMPQ CX, AX
0x0047 00071 (main.go:20) JHI 75
0x0049 00073 (main.go:20) JMP 101
0x004b 00075 (main.go:20) LEAQ (DX)(AX*8), DX
0x004f 00079 (main.go:20) MOVQ BX, (DX)
0x0052 00082 (main.go:20) JMP 84
0x0054 00084 (main.go:19) DECQ main.i+16(SP)
0x0059 00089 (main.go:19) JMP 34
0x005b 00091 (main.go:22) MOVQ 24(SP), BP
0x0060 00096 (main.go:22) ADDQ $32, SP
0x0064 00100 (main.go:22) RET
0x0065 00101 (main.go:20) PCDATA $1, $0
0x0065 00101 (main.go:20) CALL runtime.panicIndex(SB)
0x006a 00106 (main.go:20) XCHGL AX, AX
|
开启编译优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| go build -gcflags=-S main.go
0x000e 00014 (main.go:19) MOVQ main.N(SB), DX
0x0015 00021 (main.go:19) JMP 32
0x0017 00023 (main.go:20) MOVQ DX, (BX)(AX*8)
0x001b 00027 (main.go:19) DECQ DX
0x001e 00030 (main.go:19) NOP
0x0020 00032 (main.go:19) TESTQ DX, DX
0x0023 00035 (main.go:19) JLE 58
0x0025 00037 (main.go:20) MOVQ main.List+8(SB), CX
0x002c 00044 (main.go:20) MOVQ main.List(SB), BX
0x0033 00051 (main.go:20) CMPQ AX, CX
0x0036 00054 (main.go:20) JCS 23
0x0038 00056 (main.go:20) JMP 68
0x003a 00058 (main.go:22) MOVQ 16(SP), BP
0x003f 00063 (main.go:22) ADDQ $24, SP
0x0043 00067 (main.go:22) RET
0x0044 00068 (main.go:20) PCDATA $1, $0
0x0044 00068 (main.go:20) CALL runtime.panicIndex(SB)
0x0049 00073 (main.go:20) XCHGL AX, AX
|
可以看到把很多操作压在DX寄存器里操作了,不用内存取值了